深入理解Java注解处理器
一、简介
Annotation Processing Tool(APT),即Java注解处理器,是JavaX包中提供的工具。Android中并不具备此包,所以在Gradle工程中的体现形式为java-library。大名鼎鼎的ButterKnife就基于此工具而成,常用于自动生成具备一定规律的机械化代码。善加利用,可以在大型工程协作中发挥巨大的作用,从没有灵魂的代码中解放我们的双手,把每一份可贵的精力都放在更富有创造力的地方。
在ButterKnife横空出世后,APT(Annotation Processing Tool)对于Android开发者来说早已不陌生。因其可以自动生成机械化代码的特性,各类基于此的工具也层出不穷。本文会详细拆解APT周边的众多API以及深入探讨此机制背后的设计思想与逻辑,让读者对APT的理解更深一层,从而更加活学活用。
二、基础夯实
说在前面
当我们面对APT时,需要将脑子换一换。
平日里,我们是在面向runtime编程。而在面对APT时,实际面对的是编译时compile-time。此时此刻,我们所书写的代码还在编译成Class的途中,对他们的反射用法在这个环节是没什么用武之地的,代码以另外的AST格式存在于这个环节。相对应的,如果要操作它们就需要新的一套API。现在,像张无忌忘掉乾坤大挪移,重新学习太极拳一样,请大家换个脑子,面对新的领域。
注解是什么
如@Nullable这种带@符号的叫做注解。
定义注解很简单:
public @interface Foo {}
即可以生成一个叫做@Foo的注解。
生效领域
可以通过@Retention定义注解可以生效的领域,有三种:
- SOURCE,只可以在源码中存活。这种注解可以用作Lint、APT这种工作在源码上的工具,会在编译环节被编译器主动舍弃,不会存在于Class文件中
- CLASS(默认),可以存活在Class文件中,但不会在运行时被JVM加载。作用上,除覆盖前者的用途之外,这种注解可以在编译环节中生效,如class编译成dex的过程中,就可以通过transform等手段加以利用。若不需要在编译环节产生作用,则与SOURCE无异,这里建议就直接使用SOURCE
- RUNTIME,可以存活在运行时。可见,这种类型生命周期最长。功能就是大家最熟悉的反射(性能差一个数量级,还是建议少用)
作用对象
通过@Target设置,就是说明此注解可以用来修饰谁,常见的有:
- FIELD 成员变量,包含枚举类型的成员值
- METHOD 在方法上是修饰方法的返回值
- PARAMETER 修饰方法的入参
- TYPE 修饰类或接口
可以多选。
继承
@Inhertited用来表明注解的继承特性。注意,是继承特性而不是属性。注解本身并不具备继承性,这里所说的继承指的是注解所标记的类或接口的继承关系。
举个例子,注解@Foo被定义为:
1 | (TYPE) |
类A被标记:
1 | (value = 2) |
其子类B被标记为:
1 | class B extends A { |
此时,运行时可以得到:
1 | Foo f = B.getAnnotation(Foo.class) |
即,标记在A上的@Foo注解的元数据,B类得以继承。若移除@Inhertited则上述结果不可成立。
反射
反射是大家用到比较多的技巧,基础知识不再赘述,这里强调以下两方面内容:
容易忽略的几点
getDeclaredXXX()vs.getXXX()区别是前者可获取私有,后者可获取父类成员。但构造器并不存在继承的概念,所以就只有私有的区别了Class.newInstance()方法在运行时调用时和new关键字的行为是一样的,所以这并不算是反射,不存在性能问题,但切记只有公开的构造器可以这样调用- 在反射调用泛型相关定义的成员时需要注意,在运行时泛型已被擦除,其真实类型是其父类,避免产生类型不匹配的错误
反射中的泛型
这里不展开关于反射泛型的使用,只做简单介绍,用于和后边编译时的相关类型搭配比对,便于理解。
Type(java.lang.reflect.Type)是Java语言中所有类型的公共高级接口,我们最熟悉的Class就是它的实现。它存在的目的是用来描述泛型。
代码中的泛型定义会被编译器进行编译抹除,表现在runtime我们直接获取相关对象类型时拿到的是其父类类型。但其实泛型定义的描述数据依然存在于编译后的Class中,我们可以利用反射在运行时获取真正的泛型定义,最广泛的应用应该就属Gson的数据解析了
Type在SDK中除了有一个具体的实现类Class外,还有4个子接口:
- GenericArrayType 可以透过此接口获取包含泛型定义的数组中的元数据泛型信息,在Gson、haha库中均有使用
- ParameterizedType 用于描述接受泛型限定的数据定义,如
List<String>、Map<String, Object> - TypeVariable 用于描述单个被泛型定义的数据定义,如
T,Android在运行时禁止了通过此结构获取注解类型的功能。一般从方法中、类中获取泛型定义就是透过这个类型,应用比较广泛 - WildcardType 通配符的表示,即
?,可以获取通配符限定的父类型或子类型
后边会开始关注编译时,大家换换脑子。再次强调一下,运行时可用的反射相关:多数曾经在运行时依靠反射API获取的数据在编译时就需要下面所介绍的API进行获取了
三、编译时API介绍
TypeMirror
javax.lang.model.type.TypeMirror
定义
用来在编译时(APT环节可用)描述数据类型,包括:
- 原始类型(字符串、数字)
- 声明类型(类、接口)
- 数组
- 泛型
- 通配符
- null
- 返回类型
- void类型
对外提供两个特殊API:
TypeKind getKind()用以获取当前这个TypeMirror具体类型是什么(对应上边)<R,P> R accept(TypeVisitor<R, P> v, P p)使用访问者模式进行类型转换后操作,其中R是Result结果类型,P是Parameter参数类型
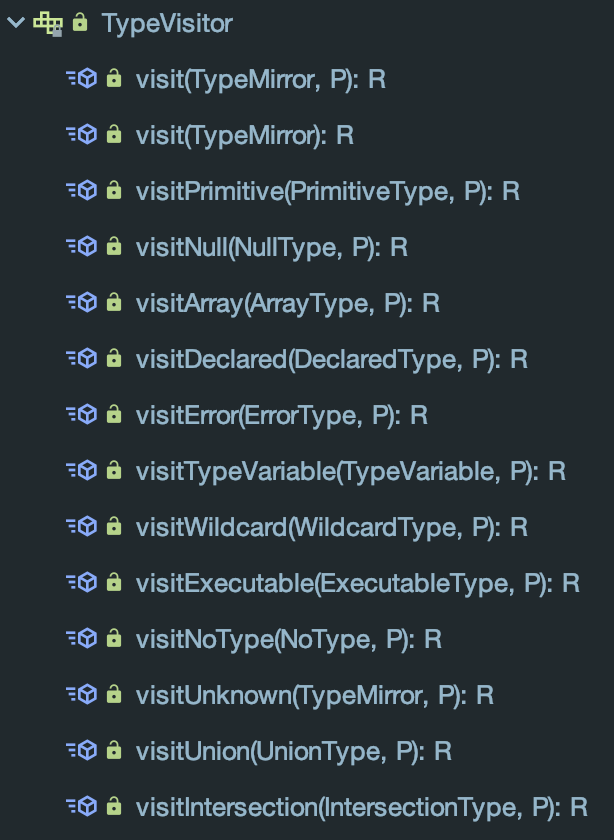
别看TypeMirror给的基础API不多,在APT的实际工作环境中,可以通过Types工具获取更多有效信息。
简单介绍一下访问者模式。
开发者作为访问者,而具备多个真实子类型的父类型作为被访问者。访问者对各个自己关心的实际类型做好准备(相关操作),整合成一个访问器,对被访问者发起访问。被访问者根据自己的真实类型以及必要的调整在访问器中挑选合适的访问回调,将操作权交还给访问者。
为什么明明可以通过
instanceof判断真实类型,还需要访问者模式?一定是在被访问者具备复杂的实现继承关系时,这种模式才有其必要性。这种做法的好处是,被访问者可以获得主动权,假设被访问者同时是“返回类型”和“数组类型”,访问者究竟该优先处理哪个的逻辑可以由被访问者主动控制。
实现
TypeMirror接口的主要具体实现:
- ArrayType 代表数组类型,可通过API获取元数据类型
- DeclaredType 声明类型,即类或接口。可以通过
asElement()和后面的Element进行转换 - ExecutableType 方法、构造器、初始化块等可执行体的类型,类似反射中Method,包含几个关键API:
List<? extends TypeVariable> getTypeVariables()获取声明中的泛型,如public <T> void foo(T t)则会得到T的TypeVariableList<? extends TypeMirror> getParameterTypes()获取入参类型TypeMirror getReturnType()获取返回值类型List<? extends TypeMirror> getThrownTypes()获取声明的异常类型
- TypeVariable 泛型类型,可以通过
getLowerBound()和getUpperBound()获取类型限定 - WildcardType 通配类型,API同上
应用
上述介绍到的TypeMirror接口的相关具体实现由Java的tools.jar完成。编译器会在编译环节将我们的代码转换成这种结构进而在编译时进行操作。
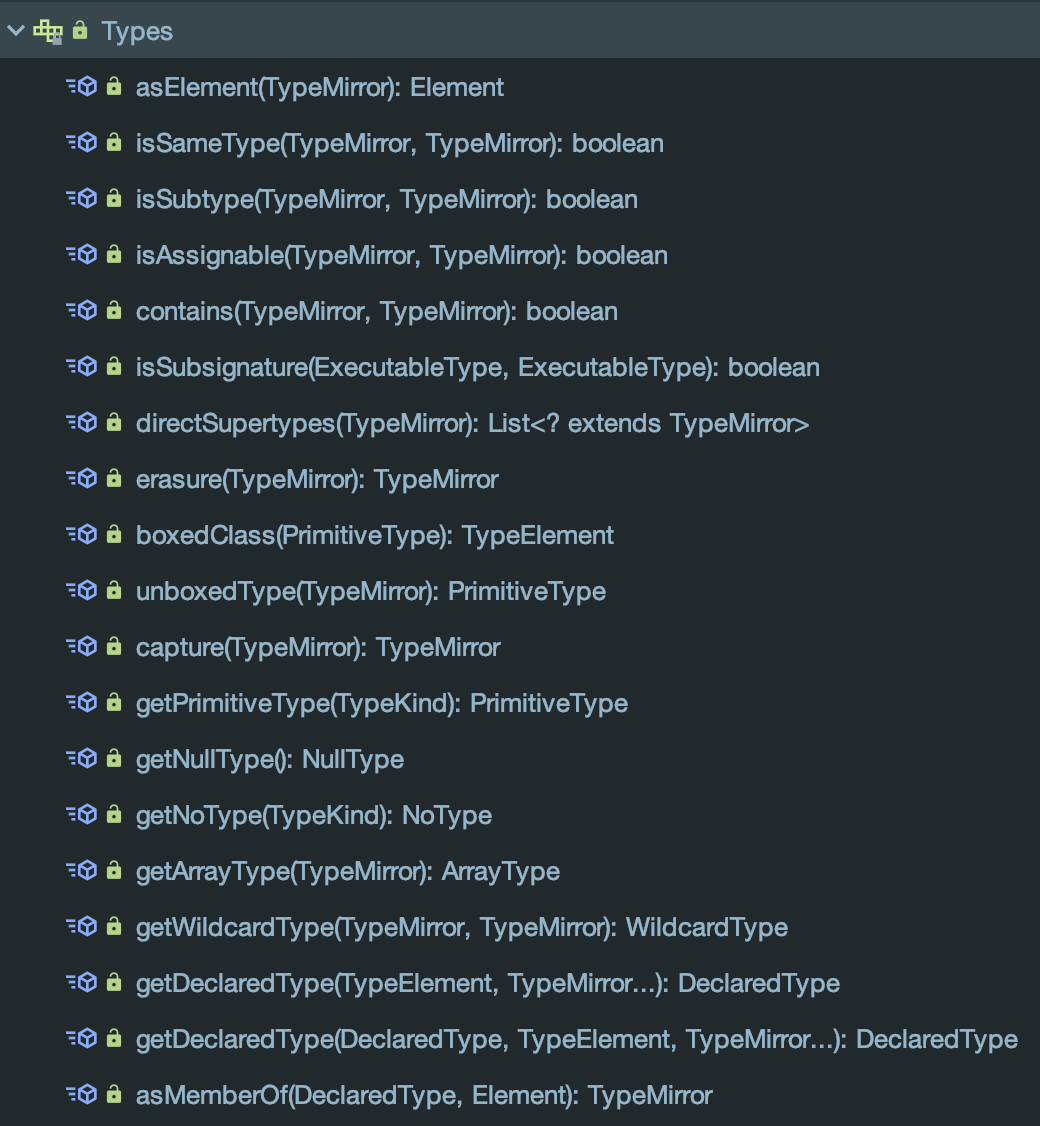
TypeMirror及相关实现接口本身具备一定API的同时,另外的操作可以由Types(javax.lang.model.util.Types)帮助完成,这个接口可以透过ProcessingEnvironment得到,这个类会在后边的Processor中提到。此工具提供的主要功能有:
- 判断类型是否相关、是否子类、父类
- 获取某类型的直接子类型
- 获取某类型擦除后的类型
- 进行装箱、拆箱操作
Element
javax.lang.model.element.Element
在APT环境中无法操作我们自己的Class,因为他们还在被编译的途中,只能通过此类及Type做相关操作。
定义
每个Element代表的是一个编程节点,比如一个包、类或方法。是语言级别的数据结构的静态表示。
关于定义的理解有两个难点:
- 如何理解“静态、语言级别”?对应的说,它们并不是虚拟机所定义的运行时结构。这里我个人的理解是:编译器在这个环节将我们的代码转化成为特定的AST(抽象语法树)结构,用Element来表示其中每一个重要“节点”。因为透出给外部的能力要有限定,所以并没有深化到语句级别。最终透过APT告诉我们:你看,我编译到这里了,有这些个节点,你需不需要做点什么?
- 与TypeMirror的区别是什么?因为两者可以部分透过API进行互相转化,所以很容易产生概念混淆
- Element是程序真正会运行到的节点,它可以具备注释
Set<String>是TypeMirror,而Set是Element。TypeMirror是对Element提供了从类型到声明的一个映射,在更高的层次上对Element进行解释说明- 粗暴的解法:Element是实例,可以透过它获得真正有效的数据。而TypeMirror是只是类型描述,无法代表实例的值。比如我们在某个Annotation中给了value是1,透过Element可以得到1,而透过TypeMirror只能得到是Integer类型
与TypeMirror一样,Element只是一个接口,特殊的API也基本一致:
ElementKind getKind()用以获取节点的具体类型<R,P> R accept(ElementVisitor<R,P> v, P p)支持外部使用访问者模式进行访问操作TypeMirror asType()这里不同于TypeMirror,所有的Element都可以进行转化- 举例说明:某Element节点有泛型声明
<N extends Number>在转化后直接得到的TypeMirror是<N>,但可以通过Types操作获取到真实数据
- 举例说明:某Element节点有泛型声明
List<? extends Element> getEnclosedElements()此节点包含了哪些子节点Element getEnclosingElement()此节点的父节点是谁
Element的类型包括:注解、类、接口、构造器、枚举、枚举值、异常参数、变量、初始化块、本地变量、方法、包、参数、资源变量、静态初始化块、泛型参数等
实现
这里介绍几个常用及重点的节点:
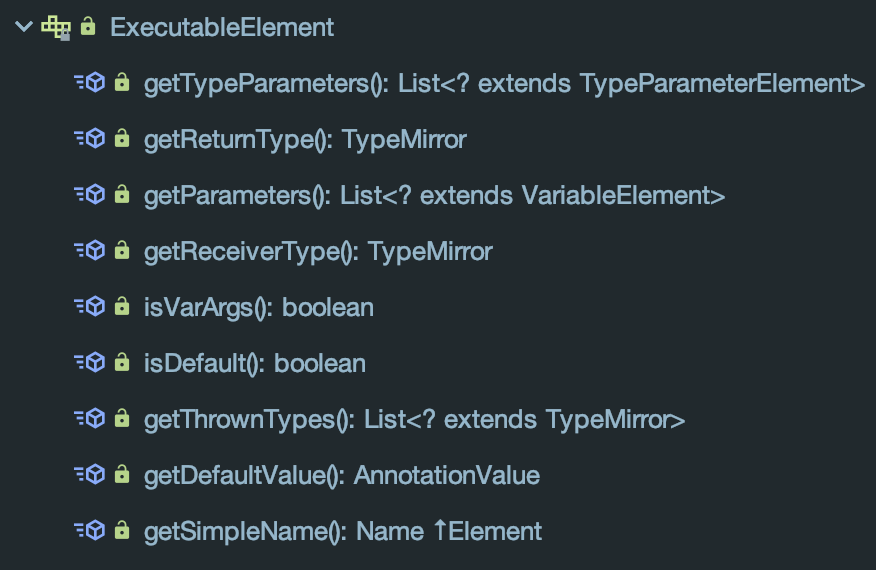
ExecutableElement 表示一个可执行节点,具备的功能和ExecutableType及其类似
TypeElement 最常见的节点,代表类或是接口节点,对应TypeMirror的DeclaredType,特殊的API有:
List<? extends TypeMirror> getInterfaces()该节点实现了哪些接口TypeMirror getSuperclass()获取直接父类List<? extends TypeParameterElement> getTypeParameters()获取该节点的泛型声明数据NestingKind getNestingKind()获取节点的嵌套类型(按下不表,后边解释)
TypeParameterElement 表示一个类、接口或方法、构造器节点的泛型定义类型
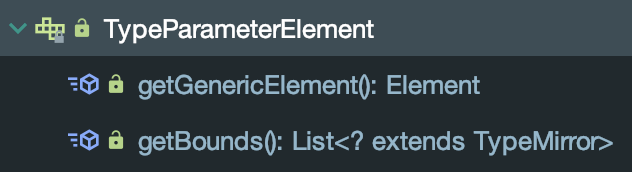
- getGenericElement() 用来获取被这个泛型定义所标识的类、接口、方法或构造函数,简单可以理解为其父元素,
getEnclosingElement()被设定成返回一样的数据 - getBounds() 返回此泛型定义的父类型,默认是Object
- getGenericElement() 用来获取被这个泛型定义所标识的类、接口、方法或构造函数,简单可以理解为其父元素,
VariableElement 一个field、枚举成员、方法或者构造器的参数、异常的参数、本地变量等都用这个结构来表达,有一个比较特殊的API:
Object getConstantValue()可以通过这个API在编译环节获取到被final修饰的原始数据或字符串类型的数据,其他的复杂类型或者没被final修饰的原始类型、字符串类型将没办法拿到,在这个环节只有final相关的值才会被编译器感知到,剩下的全是在runtime时
AnnotationMirror 注解节点。这是最特殊的Element,它并不是Element的子接口,但在这个包下,代表一个注解,可以透过它获取此注解的每一个值
DeclaredType getAnnotationType()获取这个注解的接口定义,本质上注解也是接口Map<? extends ExecutableElement, ? extends AnnotationValue> getElementValues()获取此注解中的每一项数据,结合Android Annotation的@Size理解一下: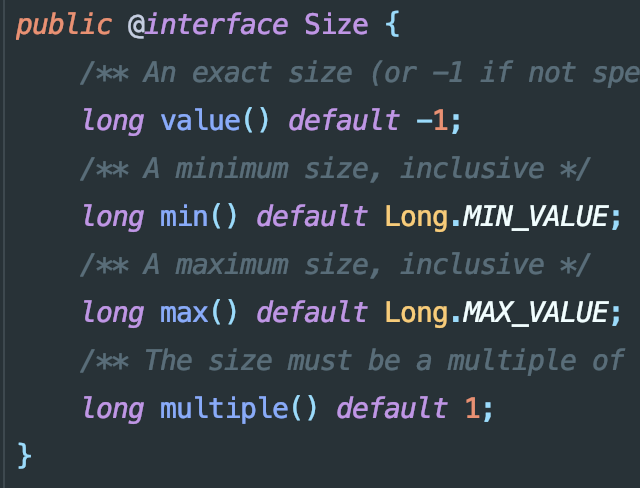
这个API会返回的Map大概示意就是
{value():long, min():long,max():long,multiple():long},这里的long就是AnnotationValue
AnnotationValue
它代表着存在于注解中的值,包含:
基本类型(装箱)
String
TypeMirror 复杂类型,比如某个类
VariableElement 枚举成员
AnnotationMirror 注解中的其他注解(嵌套使用),ButterKnife中就有相关应用:

List<? extends AnnotationValue>一组值,在已知结构时可以进行强转
其API比较简单,都是关于获取值的:
Object getValue()获得真实的值<R, P> R accept(AnnotationValueVisitor<R, P> v, P p)用访问器去获取值
实际使用中,建议通过第二种访问者模式去获取真实的值,或者参考ButterKnife的做法,直接在AnnotationProcessor中反射到某Annotation中的方法(Method),直接执行以获取返回结果。这样可行的原因是注解是作为元数据存在于编译环节的,所以其方法可执行。
嵌套类型
解释下在TypeElement环节时提到的嵌套类型NestingKind。其实现是一个枚举,包括四个成员:
- TOP_LEVEL 顶级节点,意味着没有节点可以包含它了
- MEMBER 成员命名节点,被另一个节点包含着就是成员
- LOCAL 在一个结构内被声明的命名节点
- ANONYMOUS 匿名节点
举例说明:

如上图所示,@Nesting只做标记作用,来表示每个层级对应的嵌套类型
应用
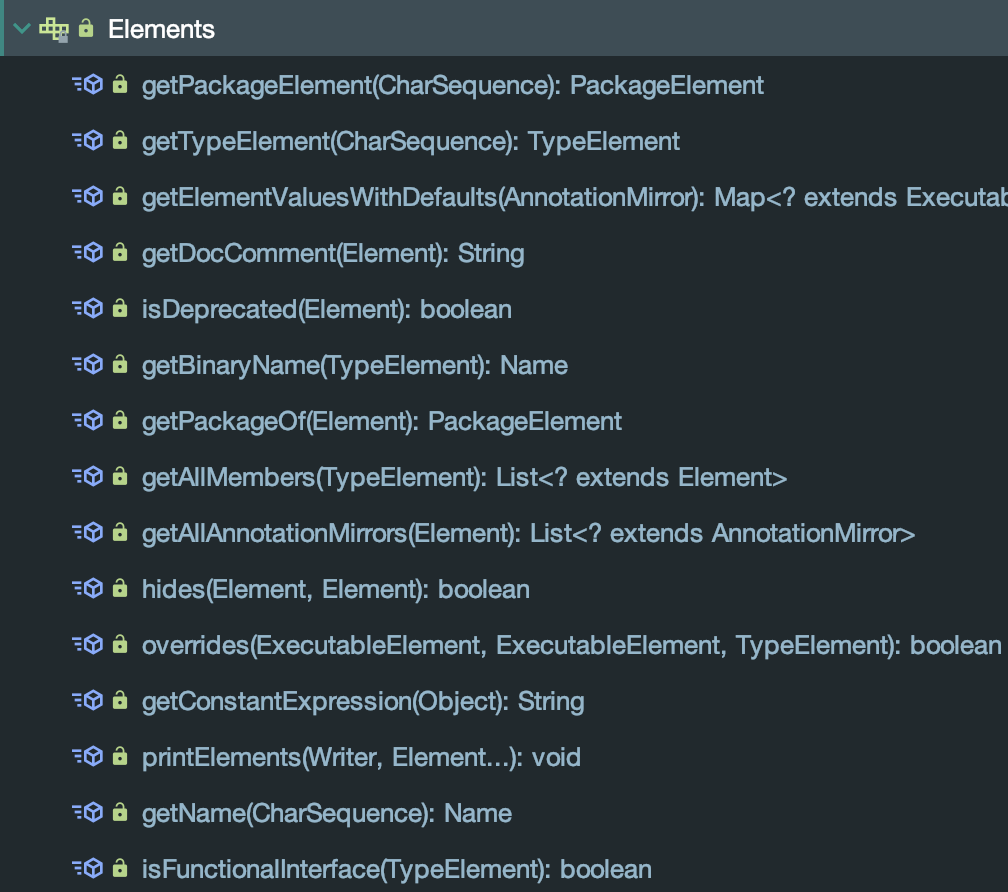
同TypeMirror一样,Element的真实实现默认只有编译器的tools.jar实现,可以在APT中透过ProcessingEnvironment获取到Elements接口对Element进行更全面的操作:
- 根据字符串找包、类或接口
- 获取节点文档、判断其是否是被废弃了
- 等等
总结
TypeMirror和Element作为在编译环节操作源码的工具,和我们常用的反射有非常多的相似之处,而在编译时,反射也不是完完全全的不能使用,比如上边所说的对Annotation元数据相关的方法反射及执行是可以生效的。呼应简介中所强调的运行时、编译时概念,读者需要加强理解,就可以在编译时将相关工具使用的得心应手了。
四、APT的应用
APT,全名为:注解处理工具(Annotation Processing Tool),负责查找注解所在并提供了操作环境的处理器。其生命周期属于编译前期,开发者可以在这样的操作环境中结合预先写好在源码中的各种注解,通过方才介绍的TypeMirror、Element等编译时API以及一些反射手段对源码进行操作。
APT技术的应用包括但不限于生成新的源码文件、报告等。常用来解决机械性的、强规律性的、重复性的代码书写工作,即可以将带有注解标记的源文件作为输入,而APT根据开发人员设定的规则生成若干派生文件。
设计思路
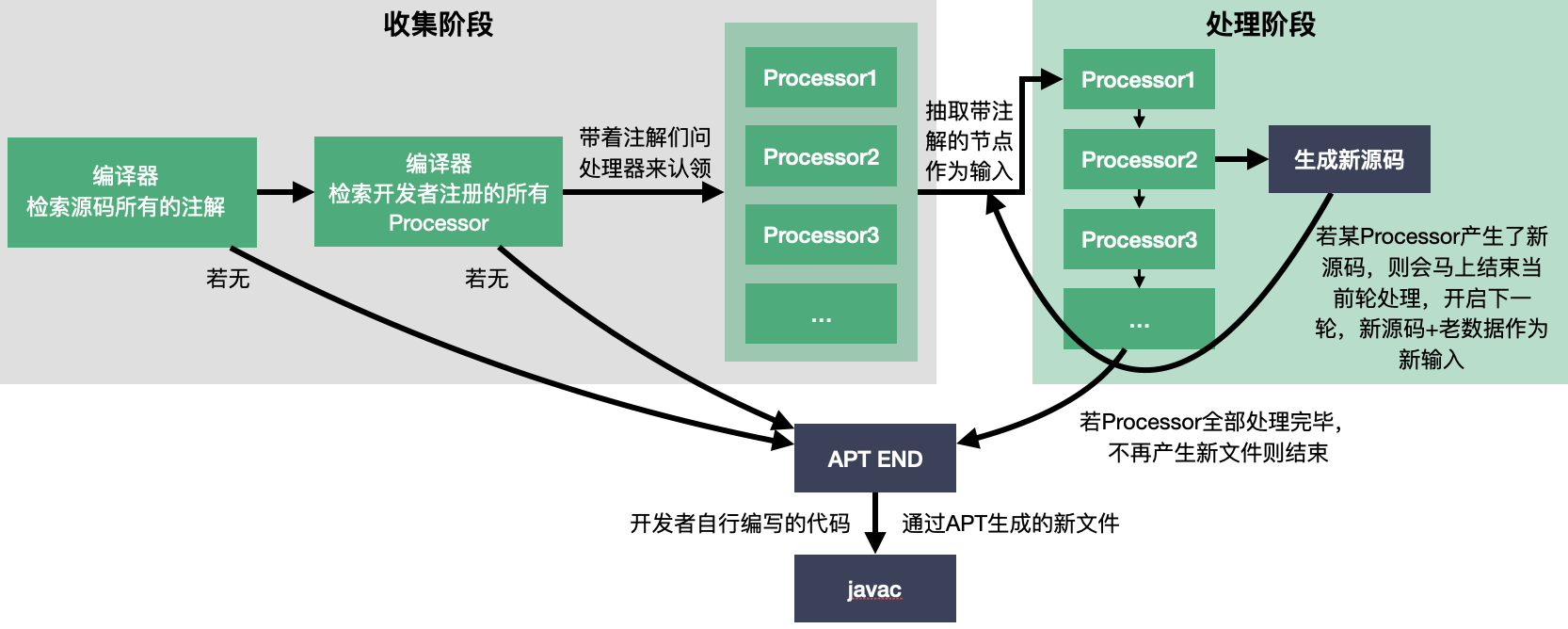
结合上图,APT的运作流程分为收集和处理两个阶段,大致如下:
收集阶段
- 编译器检查源码中所有的注解元素,如果没有则整个流程直接结束,否则继续
- 编译器检查开发者注册了哪些AnnotationProcessor,如果没有则整个流程直接结束,否则继续
- 编译器拿着所有收集到的注解元素去问Processor们进行认领
- 当所有注解类型被认领完毕,此阶段结束,进入下一阶段
- 若仍有注解类型没有被认领,但已经没有多余的处理器了,同样此阶段结束,进入下一阶段
处理阶段
- 编译器将从源码中收集到的注解元素作为输入开启一轮处理
- 所有开发者注册的注解处理器将排好队串行处理编译器传入的注解元素,在这里需要注意的是注解处理器之间并没有明确的排序规则,可以认为是乱序的,而且每一次可能不一样,不可依赖
- 若某个注解处理器在处理过程中生产出了新的源码文件,那么此轮处理会立即结束。新生成的源码文件及目前还没处理完的源码元素加在一起作为下一轮的输入(若新生成的源码中没有注解元素,其实是没有意义的)
- 新一轮处理中,所有的注解处理器依然会被触发,所以需要开发者做好识别,不要产生重复生成新文件的BUG
- 直到所有注解处理器串行处理后不再产生新文件,处理阶段结束
在处理阶段通过注解处理器产生的新源码文件会和开发者自己书写的代码一起进入javac的编译过程。
注意
在接触真正的Processor类之前,开发者有必要着重理解一下,所创建的Processor应该具备以下属性,以确保注解处理器的鲁棒性:
- 正交性。对于给定的输入,所产生的结果不应该和其他处理器的输入有关系
- 独立性。在处理给定输入时,不应该依赖某个其他的处理器的假定输出
- 统一性。对于一样的输入一定能够产生一样的输出
- 交换性。无论处理器被安排的串行顺序排位是怎样的,都应该产生一样的效果
有一种应用方式可以帮助理解:某注解处理器可以响应@A、@B,A是开发者自行在源码中标注的,而B是经过此注解处理器自动生成的源码中机器标注的。注解处理器在工作时,应该做到给什么输入就只处理输入中的相关注解,处理A时候不考虑B,两个注解的处理分开设计。
应用
javax.annotation.processing.Processor,开发者通过集成此类实现自己的注解处理器。
说在前面
APT的工作环境处在编译时,操作的对象是源码级的数据,并且对于相关的程序结构只具有只读权限。也就是说,源码作为只读数据是这个环节的输入,开发者只能产生新的文件,不能修改开发者已经写好的源码。
官方给出的建议是:
- 如无特殊说明,所有在
javax.annotation.processing包中所有方法返回的集合都是不可修改的(即使可以也没有意义,源码又不会变),并且都不是线程安全的,如果要开线程做繁重的工作,请注意做好锁保护 - 参数默认都是不允许为空的,否则会抛出NPE异常,请注意关注相关doc
注解处理器的实现
通常,实现自己的注解处理器时,继承于AbstractProcessor类。
此类首先需要实现以下三个方法:
Set<String> getSupportedOptions()表示此处理器支持通过命令行传入哪些参数,通常不需要复写返回,而且靠在此类上标注@SupportedOptions声明即可。在Gradle构建系统中,可以这样传入:1
2
3
4
5
6
7defaultConfig {
javaCompileOptions {
annotationProcessorOptions {
arguments = [ option_key : option_value ]
}
}
}Set<String> getSupportedAnnotationTypes()表示此注解器要处理(认领)的注解有哪些。同样的,通常不需要复写此方法,只需要通过在类上标注@SupportedAnnotationTypes表示即可SourceVersion getSupportedSourceVersion()表示此注解处理器所支持的最新JDK版本,默认为JDK6。通过类上标注的@SupportedSourceVersion即可说明,无需复写
另外,需要关注的两个生命周期:
void init(ProcessingEnvironment processingEnv)当此处理器被初始化时,此生命周期被调用。传入的processingEnv作为处理环境的上下文提供了很多功能,后边会详细解释boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv)最为关键的生命周期,处理器环境会携带着被注解修饰的节点(可能结合上一轮累加的)以及轮上下文(RoundEnvironment)进入此生命周期- 有一种特殊的注解处理器会声明会处理所有的注解(返回*),此时输入的Set会为空。这种处理器通常用来做编译检查、报告生成等
- 返回值表示自己是否认领相关Annotation。结合上边说的APT系统运作流程,认为这里可以是返回true代表是认领相关注解的。但因为存在另一种只要消费掉所有注解后也可停止收集阶段的设计,所以往往这里就是返回false,Google的auto-services也是如此,并不会影响最终的使用
实现一个注解处理器,最重要的环节就是在process生命周期中开始处理相关注解节点的流程了。
注解处理器的注册
两种手段:
- 官方文档做法,实现了自己的Processor实体类后,在META-INF下创建services文件夹,创建文本文件名为
javax.annotation.processing.Processor,在此文件中输入文本内容为实体类的全名 - 使用Google的auto-services,同样实现了自己的实体类后,只需要在类上标记
@AutoService(Processor.class)即可(其内部是通过上一种方法写了一个Processor收集此类元素帮助其自动生成META-INF下的注册文件)
关于ProcessingEnvironment
初始化时传入的处理器环境用来获取一些关键工具:
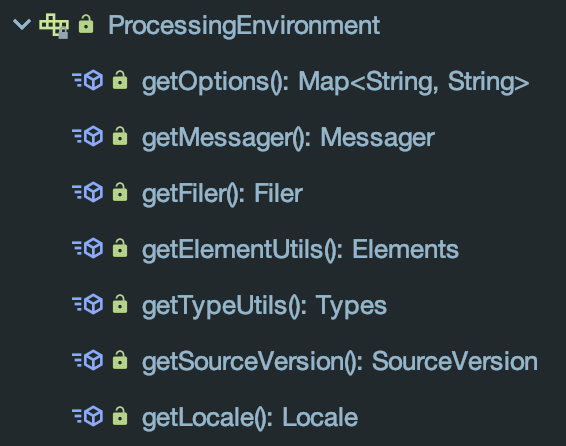
- getOptions() 即上边说到的可以透过命令行传入的相关参数键值对
- getMessager() 是编译过程中的日志组件,可以打印不同级别的信息
- getFiler() 对应提供的是文件能力,最终生成新的源码文件全靠它
- getElementUtils() 和 getTypeUtils() 就是上边说到的针对Element和TypeMirror的工具类
关于源码文件如何生成不在此文中展开说明,可以参考比较流行的javapoet,其内部做了非常友好的API封装,生成文件时可无缝对接Filer接口。
关于RoundEnvironment
如process方法文档中所说,RoundEnvironment包含了此轮以及上一轮的一些信息。其关键的API有:
Set<? extends Element> getRootElements()上一轮所产生的根节点集合(类、接口等)Set<? extends Element> getElementsAnnotatedWith(TypeElement/Class<? extends Annotation> a)通过指定的Annotation查找相关节点boolean processingOver()如果返回true说明本轮结束后将不会再开启新一轮的处理,否则是falseboolean errorRaised()上一轮是否产生了错误
如何用好processingOver和errorRaised?
存在这样一种情况,即javac在编译过程中发现有某个类找不到,会尝试再开启一轮APT,看是不是可以通过生成来补全缺失的内容。此时,被触发的Processor中透过RoundEnvironment拿到的errorRaised就是true。这种情况下,是应该继续生成代码的,以实现java尝试补全的目的。
而关于processingOver,有的Processor会有一种不太舒服的设计,就是一直缓存着之前几轮所收集的信息,直到最后一轮才真正生成文件。可能有的场景适合这样做吧,但还是建议不要一直累积,实时消费。
在单一AnnotationProcessor工作环境中,通常不会出现理解上的困难。但是一旦存在多个Processor共同在一个工程中生效,这两个API的使用就尤为重要了。当你的Processor发现上一轮产生错误时,也许是依赖着你后边的Processor产生的文件,你只要放过,只关心自己的产物即可。而如果此时是最后一轮,你确实发现了些问题,但前边的轮次中没有人报错,那么你应该担起报错的责任,让开发者能够在编译错误信息中发现端倪。
开发一个注解处理器的步骤
创建两个纯粹的
java-library工程,其中一个用于创建你的Annotation,另一个作为Processor所在工程。依赖关系上,Processor需要依赖Annotation注解的声明不做特殊说明,按照设想的功能设计好放在Annotation工程中
Processor工程中实现注解处理器的实体类,补全相关注册信息,如:

复写
init生命周期,为了两个目的:- 拿到命令行传入的参数,进行对应处理
- 获取重要的几个工具接口

正确处理在当前轮中需要做的注解操作,尽可能考虑如何应对工作在多注解处理器的环境中,简略说明如下图:

写在最后
本文花了大量的篇幅对APT相关背景及基础知识做了详尽的描述,反而显得最终讲述Processor的内容稍显单薄。实际上,要做一个注解处理器的成本是也很低的,比如刚刚把ButterKnife看个大概就完全可以花一定的时间仿照一个出来。但如果缺乏对背景和相关API的详细了解,距离灵活运用就会很远。
希望借以此文能够帮助大家理解整个APT的体系、思想,发现、发掘工作中、个人兴趣中的相关技术点,最终落实产出助力自己、助力团队。